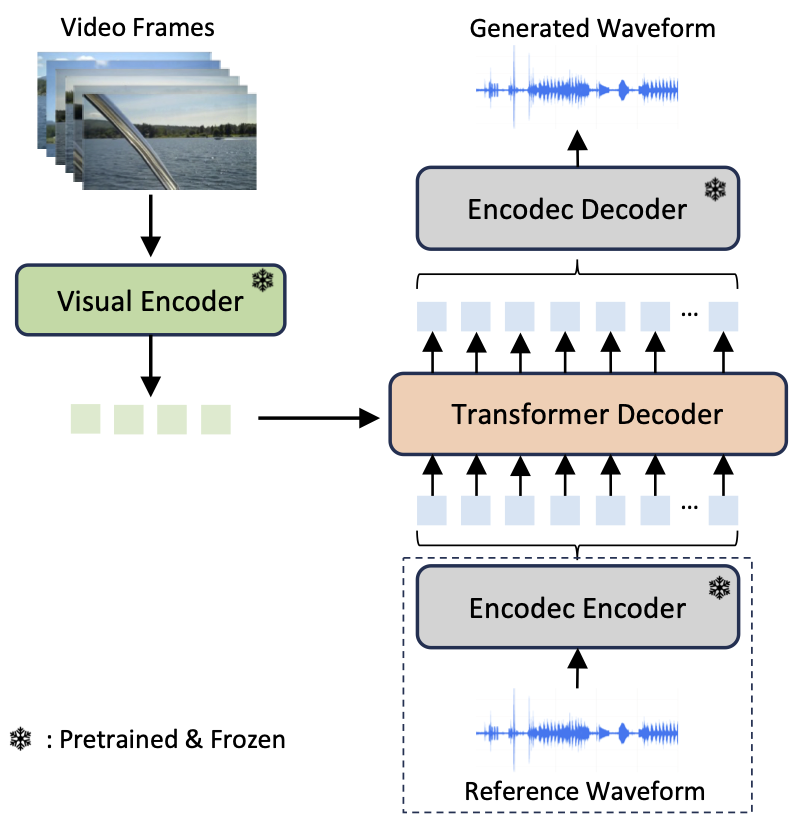
Recent advancements in audio generation tasks, such as text-to-audio and text-to-music generation, have been spurred by the evolution of deep learning models and large-scale datasets. However, the task of video-to-audio (V2A) generation continues to be a challenge, principally because of the intricate relationship between the high-dimensional visual and auditory data, and the challenges associated with temporal synchronization. In this study, we introduce \textbf{FoleyGen}, an open-domain V2A generation system built on a language modeling paradigm. FoleyGen leverages an off-the-shelf neural audio codec for bidirectional conversion between waveforms and discrete tokens. The generation of audio tokens is facilitated by a single Transformer model, which is conditioned on visual features extracted from a visual encoder. FoleyGen features two distinct versions, differentiated by how the visual features extracted by the visual encoder interact with the Transformer model. FoleyGen-C employs a cross-attention module that enables audio tokens to attend to visual features. In contrast, FoleyGen-P appends visual features directly to the audio tokens, allowing interactions within the self-attention mechanism of the Transformer. A significant challenge in V2A generation is the misalignment of generated audio with corresponding visual actions. To address this, we develop three visual attention mechanisms to assess their impact on audio-visual synchronization. Additionally, we further undertake an exhaustive evaluation of multiple visual encoders, each pretrained on either single-modal or multi-modal tasks. The experimental results on VGGSound dataset show that our proposed FoleyGen models outperforms previous systems across all objective metrics and human evaluations.